본 자료는 다음 링크의 내용을 참고하였습니다.
영화 추천 시스템
- Demographic Filtering (인구통계학적 필터링)
- Content Based Filtering (컨텐츠 기반 필터링)
- Collaborative Filtering (협업 필터링)
1. Demographic Filtering (인구통계학적 필터링)
import pandas as pd
import numpy as np
# 영화 data 로드
df1 = pd.read_csv('../data/tmdb_5000_credits.csv')
df2 = pd.read_csv('../data/tmdb_5000_movies.csv')df1.head() # csv data 상위 5개 확인| movie_id | title | cast | crew | |
|---|---|---|---|---|
| 0 | 19995 | Avatar | [{"cast_id": 242, "character": "Jake Sully", "... | [{"credit_id": "52fe48009251416c750aca23", "de... |
| 1 | 285 | Pirates of the Caribbean: At World's End | [{"cast_id": 4, "character": "Captain Jack Spa... | [{"credit_id": "52fe4232c3a36847f800b579", "de... |
| 2 | 206647 | Spectre | [{"cast_id": 1, "character": "James Bond", "cr... | [{"credit_id": "54805967c3a36829b5002c41", "de... |
| 3 | 49026 | The Dark Knight Rises | [{"cast_id": 2, "character": "Bruce Wayne / Ba... | [{"credit_id": "52fe4781c3a36847f81398c3", "de... |
| 4 | 49529 | John Carter | [{"cast_id": 5, "character": "John Carter", "c... | [{"credit_id": "52fe479ac3a36847f813eaa3", "de... |
# df2.head(3) # csv data 상위 3개 확인df1.shape, df2.shape # shape 확인((4803, 4), (4803, 20))df1['title'].equals(df2['title']) # 동일 컴럼 확인Truedf1.columns # df1 컬럼명 확인Index(['movie_id', 'title', 'cast', 'crew'], dtype='object')df1.columns = ['id', 'title', 'cast', 'crew'] # df1 컬럼명 변경
df1.columnsIndex(['id', 'title', 'cast', 'crew'], dtype='object')df1[['id', 'cast', 'crew']].head() # df1 data 확인| id | cast | crew | |
|---|---|---|---|
| 0 | 19995 | [{"cast_id": 242, "character": "Jake Sully", "... | [{"credit_id": "52fe48009251416c750aca23", "de... |
| 1 | 285 | [{"cast_id": 4, "character": "Captain Jack Spa... | [{"credit_id": "52fe4232c3a36847f800b579", "de... |
| 2 | 206647 | [{"cast_id": 1, "character": "James Bond", "cr... | [{"credit_id": "54805967c3a36829b5002c41", "de... |
| 3 | 49026 | [{"cast_id": 2, "character": "Bruce Wayne / Ba... | [{"credit_id": "52fe4781c3a36847f81398c3", "de... |
| 4 | 49529 | [{"cast_id": 5, "character": "John Carter", "c... | [{"credit_id": "52fe479ac3a36847f813eaa3", "de... |
df2 = df2.merge(df1[['id', 'cast', 'crew']], on='id') # 'id' 기준으로 df2 + df1 dataframe 병합
# df2.head(3)평점을 매긴 인원수에 따른 신뢰도 차이 때문에 평점의 가중치를 적용한 식 적용 (kaggle 참고)
# 평점 평균
C = df2['vote_average'].mean()
C6.092171559442016# 평가의 수(인원)가 상위 10% 되는 값
m = df2['vote_count'].quantile(0.9)
m1838.4000000000015# m (평가의 수) 보다 많은 데이터만 필터
q_movies = df2.copy().loc[df2['vote_count'] >= m]
q_movies.shape(481, 22)q_movies['vote_count'].sort_values() # 'vote_count' 열 데이터 오름차순 정렬2585 1840
195 1851
2454 1859
597 1862
1405 1864
...
788 10995
16 11776
0 11800
65 12002
96 13752
Name: vote_count, Length: 481, dtype: int64# 가중치를 적용한 식
def weighted_rating(x, m=m, C=C):
v = x['vote_count']
R = x['vote_average']
return (v / (v + m) * R) + (m / (m + v) * C)# 'score' 열 생성 -> weighted_rating 함수 적용한 가중치 점수
q_movies['score'] = q_movies.apply(weighted_rating, axis=1) # axis= 1 (행 기준), 0 (열 기준)
# q_movies.head(3)q_movies = q_movies.sort_values('score', ascending=False) # 'score' 열 data 내림차순 정렬
q_movies[['title', 'vote_count', 'vote_average', 'score']].head(10)| title | vote_count | vote_average | score | |
|---|---|---|---|---|
| 1881 | The Shawshank Redemption | 8205 | 8.5 | 8.059258 |
| 662 | Fight Club | 9413 | 8.3 | 7.939256 |
| 65 | The Dark Knight | 12002 | 8.2 | 7.920020 |
| 3232 | Pulp Fiction | 8428 | 8.3 | 7.904645 |
| 96 | Inception | 13752 | 8.1 | 7.863239 |
| 3337 | The Godfather | 5893 | 8.4 | 7.851236 |
| 95 | Interstellar | 10867 | 8.1 | 7.809479 |
| 809 | Forrest Gump | 7927 | 8.2 | 7.803188 |
| 329 | The Lord of the Rings: The Return of the King | 8064 | 8.1 | 7.727243 |
| 1990 | The Empire Strikes Back | 5879 | 8.2 | 7.697884 |
# 새로 생성한 dataframe -> q_movies의 'score' 열 기준 그래프 생성
pop= q_movies.sort_values('score', ascending=False)
import matplotlib.pyplot as plt
plt.figure(figsize=(12,4))
plt.barh(q_movies['title'].head(10),q_movies['score'].head(10), align='center', # 상위 10개 데이터
color='skyblue')
plt.gca().invert_yaxis() # 가로 세로 변환
plt.xlabel("Score")
plt.title("Score")Text(0.5, 1.0, 'Score')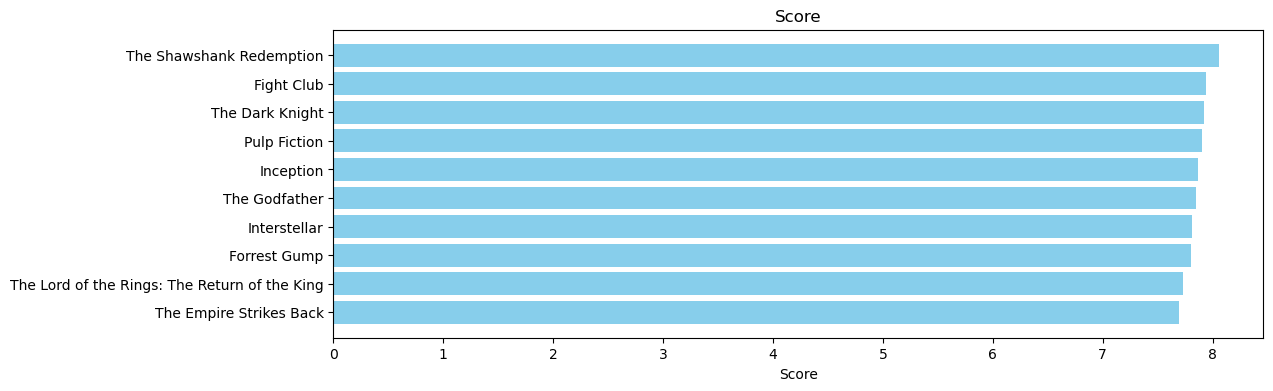
# 기존 dataframe 'popularity' 열 기준 그래프 생성
pop= df2.sort_values('popularity', ascending=False)
plt.figure(figsize=(12,4))
plt.barh(pop['title'].head(10),pop['popularity'].head(10), align='center', # 상위 10개 데이터
color='pink')
plt.gca().invert_yaxis() # 가로 세로 변환
plt.xlabel("Popularity")
plt.title("Popular Movies")Text(0.5, 1.0, 'Popular Movies')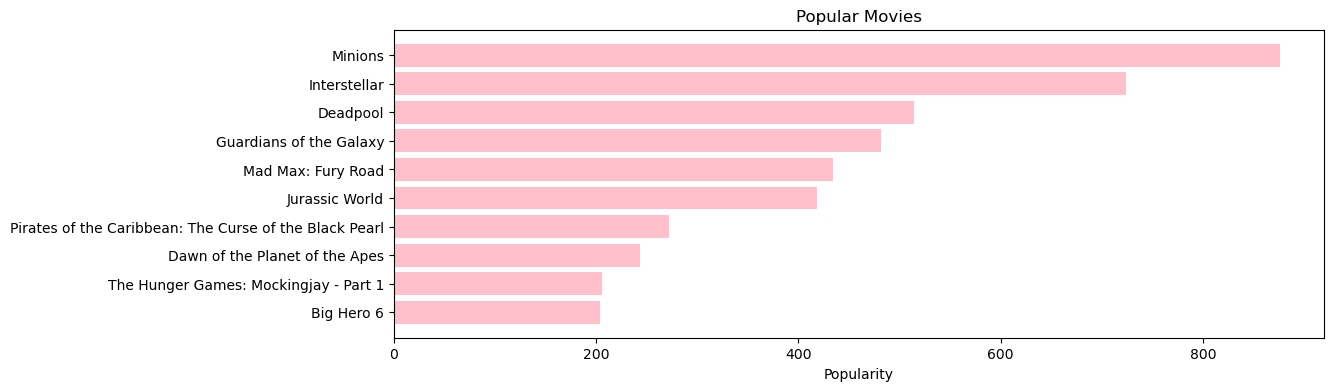
2. Content Based Filtering (컨텐츠 기반 필터링)
줄거리 기반 추천
- TfidfVectorizer 모듈 텍스트 벡터화 사용
- linear_kernel 모듈 벡터 유사도 사용
df2['overview'].head(5) # df2 'overview' 상위 5개 데이터 확인0 In the 22nd century, a paraplegic Marine is di...
1 Captain Barbossa, long believed to be dead, ha...
2 A cryptic message from Bond’s past sends him o...
3 Following the death of District Attorney Harve...
4 John Carter is a war-weary, former military ca...
Name: overview, dtype: objectfrom sklearn.feature_extraction.text import TfidfVectorizer
# 텍스트 전처리: 불필요한 단어(예: the, is, and 등)를 제거하여 모델의 성능을 향상: stop_words='english'
tfidf = TfidfVectorizer(stop_words='english')from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
ENGLISH_STOP_WORDS # 중요치 않은 영어 요소 확인frozenset({'a',
'about',
'above',
'across',
'after',
'afterwards',
'again',
'against',
'all',
'almost',
'alone',
'along',
'already',
'also',
'although',
'always',
'am',
'among',
'amongst',
'amoungst',
'amount',
'an',
'and',
'another',
'any',
'anyhow',
'anyone',
'anything',
'anyway',
'anywhere',
'are',
'around',
'as',
'at',
...생략
})df2['overview'].isnull().values.any() # null 값 확인Truedf2['overview'] = df2['overview'].fillna('') # null 채우기 -> ''- TfidfVectorizer (TF-IDF 기반의 벡터화) - am, a, the등 be동사나 관사등 중요하지 않다고 판단되는 단어는 중요치를 낮춤
tfidf_matrix = tfidf.fit_transform(df2['overview'])
tfidf_matrix.shape # 4803 개의 문서들이 20978개의 단어 형태(4803, 20978)tfidf_matrix # 125840 개의 데이터 존재<4803x20978 sparse matrix of type '<class 'numpy.float64'>'
with 125840 stored elements in Compressed Sparse Row format>from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix) # linear_kernel 모듈 이용하여 벡터화한 단어들의 유사도 데이터 생성
cosine_sim # 데이터 형태 확인array([[1. , 0. , 0. , ..., 0. , 0. ,
0. ],
[0. , 1. , 0. , ..., 0.02160533, 0. ,
0. ],
[0. , 0. , 1. , ..., 0.01488159, 0. ,
0. ],
...,
[0. , 0.02160533, 0.01488159, ..., 1. , 0.01609091,
0.00701914],
[0. , 0. , 0. , ..., 0.01609091, 1. ,
0.01171696],
[0. , 0. , 0. , ..., 0.00701914, 0.01171696,
1. ]])cosine_sim.shape(4803, 4803)# 'title' 열의 값을 인덱스로 하여 시리즈 생성
indices = pd.Series(df2.index, index=df2['title']).drop_duplicates() # 열에 중복된 값이 있다면, 첫 번째 항목만 유지되고 나머지는 제거
indicestitle
Avatar 0
Pirates of the Caribbean: At World's End 1
Spectre 2
The Dark Knight Rises 3
John Carter 4
...
El Mariachi 4798
Newlyweds 4799
Signed, Sealed, Delivered 4800
Shanghai Calling 4801
My Date with Drew 4802
Length: 4803, dtype: int64indices['The Dark Knight Rises'] # title 로 인덱스 검색 -> 33# df2.iloc[[3]] # 3번째 인덱스 데이터 확인# 영화의 제목을 입력받으면 코사인 유사도를 통해서 가장 유사도가 높은 상위 10개의 영화 목록 반환 하는 함수 생성
def get_recommendations(title, cosine_sim=cosine_sim):
# 영화 제목을 통해서 전체 데이터 기준 그 영화의 index 값을 얻기
idx = indices[title]
# 코사인 유사도 매트릭스 (cosine_sim) 에서 idx 에 해당하는 데이터를 (idx, 유사도) 형태로 얻기
sim_scores = list(enumerate(cosine_sim[idx]))
# 코사인 유사도 기준으로 내림차순 정렬
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 자기 자신을 제외한 10개의 추천 영화를 슬라이싱 (점수가 높을수록 유사도 높음)
sim_scores = sim_scores[1:11]
# 추천 영화 목록 10개의 인덱스 정보 추출
movie_indices = [i[0] for i in sim_scores]
# 인덱스 정보를 통해 영화 제목 추출
return df2['title'].iloc[movie_indices]get_recommendations('Avengers: Age of Ultron') # 함수 적용 확인16 The Avengers
79 Iron Man 2
68 Iron Man
26 Captain America: Civil War
227 Knight and Day
31 Iron Man 3
1868 Cradle 2 the Grave
344 Unstoppable
1922 Gettysburg
531 The Man from U.N.C.L.E.
Name: title, dtype: objectget_recommendations('The Avengers') # 함수 적용 확인7 Avengers: Age of Ultron
3144 Plastic
1715 Timecop
4124 This Thing of Ours
3311 Thank You for Smoking
3033 The Corruptor
588 Wall Street: Money Never Sleeps
2136 Team America: World Police
1468 The Fountain
1286 Snowpiercer
Name: title, dtype: object다양한 요소 기반 추천 (장르, 감독, 키워드 등)
- CountVectorizer 모듈 텍스트 벡터화 사용
- cosine_similarity 모듈 벡터 유사도 사용
# df2.head(3) # 데이터 확인df2.loc[0, 'genres'] # 0번째 인덱스 'genres' 열 데이터 확인'[{"id": 28, "name": "Action"}, {"id": 12, "name": "Adventure"}, {"id": 14, "name": "Fantasy"}, {"id": 878, "name": "Science Fiction"}]'s1 = [{"id": 28, "name": "Action"}]
s2 = '[{"id": 28, "name": "Action"}]'from ast import literal_eval # 문자형태의 문자열 데이터를 자료형으로 변환
s2 = literal_eval(s2)
s2, type(s2)([{'id': 28, 'name': 'Action'}], list)# 4개의 자료형 형태인 문자열 데이터 -> 문자열 데이터를 자료형으로 변환
features = ['cast', 'crew', 'keywords', 'genres']
for feature in features:
df2[feature] = df2[feature].apply(literal_eval)df2.loc[0, 'crew'][0] # crew 열의 변환된 첫번째 데이터 확인{'credit_id': '52fe48009251416c750aca23',
'department': 'Editing',
'gender': 0,
'id': 1721,
'job': 'Editor',
'name': 'Stephen E. Rivkin'}# 감독 이름 추출
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
return np.nan # name 정보 없을 경우 nan# 'crew' 컬럼 데이터에 get_director함수 적용하여 'director' 컬럼 생성 -> 감독 이름 저장
df2['director'] = df2['crew'].apply(get_director)
df2['director']0 James Cameron
1 Gore Verbinski
2 Sam Mendes
3 Christopher Nolan
4 Andrew Stanton
...
4798 Robert Rodriguez
4799 Edward Burns
4800 Scott Smith
4801 Daniel Hsia
4802 Brian Herzlinger
Name: director, Length: 4803, dtype: object# df2[df2['director'].isnull()] # nan 데이터 확인df2.loc[0, 'cast'][0] # 데이터 확인{'cast_id': 242,
'character': 'Jake Sully',
'credit_id': '5602a8a7c3a3685532001c9a',
'gender': 2,
'id': 65731,
'name': 'Sam Worthington',
'order': 0}df2.loc[0, 'genres'][0] # 데이터 확인{'id': 28, 'name': 'Action'}df2.loc[0, 'keywords'][0] # 데이터 확인{'id': 1463, 'name': 'culture clash'}df2[['title', 'cast', 'director', 'keywords', 'genres']].head(3) # df2 데이터 업데이트 하기 전 데이터 확인| title | cast | director | keywords | genres | |
|---|---|---|---|---|---|
| 0 | Avatar | [{'cast_id': 242, 'character': 'Jake Sully', '... | James Cameron | [{'id': 1463, 'name': 'culture clash'}, {'id':... | [{'id': 28, 'name': 'Action'}, {'id': 12, 'nam... |
| 1 | Pirates of the Caribbean: At World's End | [{'cast_id': 4, 'character': 'Captain Jack Spa... | Gore Verbinski | [{'id': 270, 'name': 'ocean'}, {'id': 726, 'na... | [{'id': 12, 'name': 'Adventure'}, {'id': 14, '... |
| 2 | Spectre | [{'cast_id': 1, 'character': 'James Bond', 'cr... | Sam Mendes | [{'id': 470, 'name': 'spy'}, {'id': 818, 'name... | [{'id': 28, 'name': 'Action'}, {'id': 12, 'nam... |
# 처음 3개의 데이터 중에서 name 에 해당하는 value 만 추출
def get_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
if len(names) > 3:
names = names[:3]
return names
return []# 각 컬럼 데이터에 get_list함수 적용하여 각 컬럼 업데이트 -> name 데이터 3개 저장
features = ['cast', 'keywords', 'genres']
for feature in features:
df2[feature] = df2[feature].apply(get_list)df2[['title', 'cast', 'director', 'keywords', 'genres']].head(3) # df2 업데이트| title | cast | director | keywords | genres | |
|---|---|---|---|---|---|
| 0 | Avatar | [Sam Worthington, Zoe Saldana, Sigourney Weaver] | James Cameron | [culture clash, future, space war] | [Action, Adventure, Fantasy] |
| 1 | Pirates of the Caribbean: At World's End | [Johnny Depp, Orlando Bloom, Keira Knightley] | Gore Verbinski | [ocean, drug abuse, exotic island] | [Adventure, Fantasy, Action] |
| 2 | Spectre | [Daniel Craig, Christoph Waltz, Léa Seydoux] | Sam Mendes | [spy, based on novel, secret agent] | [Action, Adventure, Crime] |
# 각 컬럼 데이터 전처리
# James Cameron 이라는 하나의 이름 데이터에는 공백과 대소문자가를 포함하는데 분류해서 처리 하면 안되기 때문에 공백 제거 및 소문자 변환 처리
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(' ', '')) for i in x]
else:
if isinstance(x, str):
return str.lower(x.replace(' ', ''))
else:
return ''# 각 컬럼 데이터에 clean_data함수 적용하여 각 컬럼 업데이트 -> 공백 제거 및 소문자 변환
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
df2[feature] = df2[feature].apply(clean_data)df2[['title', 'cast', 'director', 'keywords', 'genres']].head(3) # df2 업데이| title | cast | director | keywords | genres | |
|---|---|---|---|---|---|
| 0 | Avatar | [samworthington, zoesaldana, sigourneyweaver] | jamescameron | [cultureclash, future, spacewar] | [action, adventure, fantasy] |
| 1 | Pirates of the Caribbean: At World's End | [johnnydepp, orlandobloom, keiraknightley] | goreverbinski | [ocean, drugabuse, exoticisland] | [adventure, fantasy, action] |
| 2 | Spectre | [danielcraig, christophwaltz, léaseydoux] | sammendes | [spy, basedonnovel, secretagent] | [action, adventure, crime] |
# 'soup' 컬럼 생성 -> 'keywords', 'cast', 'director', 'genres' 열 데이터를 하나의 문자열로 변환함
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])
df2['soup'] = df2.apply(create_soup, axis=1) # axis=1은 각 행(row)에 대해 create_soup 함수를 호출
df2['soup'].head()0 cultureclash future spacewar samworthington zo...
1 ocean drugabuse exoticisland johnnydepp orland...
2 spy basedonnovel secretagent danielcraig chris...
3 dccomics crimefighter terrorist christianbale ...
4 basedonnovel mars medallion taylorkitsch lynnc...
Name: soup, dtype: object- CountVectorizer - 모든 단어에 대해서 카운트
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(df2['soup'])
count_matrix
# 4803 개의 row, 11520 개의 colimn, 42935 개의 유효한 데이터
# 4803개의 문서에서 11520개의 고유 단어를 추출하여 생성한 단어-문서 행렬
# 전체 4803 × 11520 = 55,330,560개의 요소 중 약 0.078%만 0이 아닌 값<4803x11520 sparse matrix of type '<class 'numpy.int64'>'
with 42935 stored elements in Compressed Sparse Row format>from sklearn.metrics.pairwise import cosine_similarity
cosine_sim2 = cosine_similarity(count_matrix, count_matrix) # cosine_similarity 모듈 이용하여 벡터화한 단어들의 유사도 데이터 생성
cosine_sim2array([[1. , 0.3, 0.2, ..., 0. , 0. , 0. ],
[0.3, 1. , 0.2, ..., 0. , 0. , 0. ],
[0.2, 0.2, 1. , ..., 0. , 0. , 0. ],
...,
[0. , 0. , 0. , ..., 1. , 0. , 0. ],
[0. , 0. , 0. , ..., 0. , 1. , 0. ],
[0. , 0. , 0. , ..., 0. , 0. , 1. ]])get_recommendations('The Dark Knight Rises', cosine_sim2)65 The Dark Knight
119 Batman Begins
4638 Amidst the Devil's Wings
1196 The Prestige
3073 Romeo Is Bleeding
3326 Black November
1503 Takers
1986 Faster
303 Catwoman
747 Gangster Squad
Name: title, dtype: objectindices['Batman Begins']119df2.loc[119] # 데이터 확인budget 150000000
genres [action, crime, drama]
homepage http://www2.warnerbros.com/batmanbegins/index....
id 272
keywords [himalaya, martialarts, dccomics]
original_language en
original_title Batman Begins
overview Driven by tragedy, billionaire Bruce Wayne ded...
popularity 115.040024
production_companies [{"name": "DC Comics", "id": 429}, {"name": "L...
production_countries [{"iso_3166_1": "GB", "name": "United Kingdom"...
release_date 2005-06-10
revenue 374218673
runtime 140.0
spoken_languages [{"iso_639_1": "en", "name": "English"}, {"iso...
status Released
tagline Evil fears the knight.
title Batman Begins
vote_average 7.5
vote_count 7359
cast [christianbale, michaelcaine, liamneeson]
crew [{'credit_id': '52fe4230c3a36847f800ac6d', 'de...
director christophernolan
soup himalaya martialarts dccomics christianbale mi...
Name: 119, dtype: objectimport pickle# df2.head(3)movies = df2[['id', 'title']].copy()
movies.head(5)| id | title | |
|---|---|---|
| 0 | 19995 | Avatar |
| 1 | 285 | Pirates of the Caribbean: At World's End |
| 2 | 206647 | Spectre |
| 3 | 49026 | The Dark Knight Rises |
| 4 | 49529 | John Carter |
Python 객체 저장
with open('movies.pickle', 'wb') as file:
pickle.dump(movies, file)with open('cosine_sim.pickle', 'wb') as file:
pickle.dump(cosine_sim2, file)개념 정리
- 텍스트 벡터화와 유사도를 구하는 과정에서 모듈을 비교하여 검색해보며 정리함
Bag Of Words - BOW
텍스트에 포함된 모든 단어들이 순서 상관없이 몇번 씩 나왔는지 카운트
문장1 : I am a boy
문장2 : I am a girl
| i | am | a | boy | girl | |
|---|---|---|---|---|---|
| 문장1 (I am a boy) | 1 | 1 | 1 | 1 | 0 |
| 문장2 (I am a girl) | 1 | 1 | 1 | 0 | 1 |
| 단어 합계 | 2 | 2 | 2 | 1 | 1 |
피처 벡터화.
I(2), am(2), a(2), boy(1), girl(1)
| 단어1 | 단어2 | 단어3 | ... 단어 10,000 | |
|---|---|---|---|---|
| 문서1 | 1 | 3 | 1 | 5 |
| 문서2 | 6 | 1 | 1 | 9 |
| .... | . | . | . | . |
| 문서100 | 10 | 2 | 5 | 0 |
| 단어 합계 | 17 | 6 | 4 | 7 |
문서 100개
모든 문서에서 나온 단어 10,000 개
100 * 10,000 = 100만
1. 텍스트를 벡터화 하여 유사도를 구함
텍스트 벡터화
TfidfVectorizer vs CountVectorizer
| TfidfVectorizer | CountVectorizer | |
|---|---|---|
| 계산 기준 | 단어 빈도 (Frequency) | 단어 빈도 + 문서 간 중요도 (TF-IDF) |
| 빈출 단어 영향 | 많이 등장하는 단어의 값이 매우 커질 수 있음 | 자주 등장하는 단어에 가중치가 감소 |
| 희귀 단어 반영 | 고려하지 않음 | 드물게 등장하는 단어에 더 높은 가중치 부여 |
| 사용 예시 | 단순 빈도 분석, 단어 카운트 기반 모델 | 정보 검색, 추천 시스템, 문서 분류 |
언제 사용해야 할까?
- CountVectorizer: 데이터가 적고 단순한 빈도 기반 분석을 할 때 적합.
- TfidfVectorizer: 단어의 중요도(특정 문서에서만 유의미한 단어)를 반영하고 싶을 때 적합.
추천 시스템이나 문서 간 유사도 계산에 많이 사용
한글 벡터화 할때는 불용어 어떻게 제거 할까?
※한글 불용어 제거
- 사용자 정의 한국어 불용어 리스트
# 예제 한글 불용어 리스트
korean_stop_words = {"이", "그", "저", "것", "수", "을", "를", "은", "는", "에", "의", "와", "과", "에서", "하고"}
# 불용어 제거 함수
def remove_korean_stop_words(text):
words = text.split() # 공백 기준으로 나누기
filtered_words = [word for word in words if word not in korean_stop_words]
return " ".join(filtered_words)
# 예제 텍스트
text = "이 문장은 예제 문장으로 불용어를 제거하는 데 사용됩니다."
# 적용
filtered_text = remove_korean_stop_words(text)
print(filtered_text)문장은 예제 문장으로 불용어를 제거하는 데 사용됩니다.- KoNLpy 모듈 활용
pip install konlpy
from konlpy.tag import Okt
# Okt 형태소 분석기
okt = Okt()
# 예제 텍스트
text = "이 문장은 예제 문장으로 불용어를 제거하는 데 사용됩니다."
# 불용어 리스트
korean_stop_words = {"이", "그", "저", "것", "수", "을", "를", "은", "는", "에", "의", "와", "과", "에서", "하고"}
# 불용어 제거 함수
def remove_stop_words_konlpy(text):
tokens = okt.morphs(text) # 형태소 단위로 분리
filtered_tokens = [token for token in tokens if token not in korean_stop_words]
return " ".join(filtered_tokens)
# 적용
filtered_text = remove_stop_words_konlpy(text)
print(filtered_text)문장 예제 문장 으로 불 용어 제거 하는 데 사용 됩니다 .2. 벡터화한 텍스트를 유사도 계산
linear_kernel vs cosine_similarity
| linear_kernel | cosine_similarity | |
|---|---|---|
| 계산 기준 | 두 벡터의 내적 | 두 벡터의 코사인 값 |
| 값의 범위 | 제한 없음 (벡터 크기 포함) | [-1(완전히 반대), 1(완전히 같은 방향)] (벡터 방향 비교) |
| 정규화 여부 | 벡터 크기를 고려하지 않음 | 벡터 크기를 정규화 |
| 유사도 기준 | 벡터 방향과 크기 모두 고려 | 벡터 방향만 고려 |
| 메모리/속도 효율성 | 더 빠름 (정규화 필요 없음) | 상대적으로 느릴 수 있음 (정규화 포함) |
| 주요 용도 | 텍스트 유사도, 클러스터링, 정보 검색 | 머신러닝 커널 함수, 선형 모델 |
- linear_kernel (크기와 방향 둘 다 고려)
- 목적: 두 벡터를 그냥 곱해서(내적) 비슷한 정도를 계산 (벡터의 크기도 영향)
- 값의 범위: 제한 없음 (크기가 큰 벡터일수록 값이 커질 수 있음)
- 단순히 벡터의 크기와 방향을 모두 고려한 유사도
- 예: "apple"을 많이 포함한 긴 문서가 크기가 작은 문서보다 더 높은 점수를 받을 수 있음
- cosine_similarity (크기 무시하고 방향만 비교)
- 목적: 두 벡터의 방향이 얼마나 비슷한지 비교합니다 (벡터의 크기는 영향 없음)
- 값의 범위: -1(완전히 반대) ~ 1(완전히 같은 방향)
- 벡터가 같은 방향으로 있으면 유사도가 1에 가까움
- 예: 두 문서에 "apple"과 "banana"가 똑같이 포함되었다면 유사도가 높게 나옴
어떤 것을 선택할까?
linear_kernel을 사용할 때:
벡터의 크기 자체가 의미가 있는 경우.
예: 선형 분류(SVM), 회귀 모델에서 커널로 활용.cosine_similarity를 사용할 때:
벡터 크기가 의미 없고 방향만 중요한 경우.
예: 문서 유사도 계산 (TF-IDF 기반 검색).
코사인 유사도 '문장1' 문장과 가장 유사도가 가장 높은 문장은 '문장1' -> 1 (같은 문장)
'문장1' 기준으로 유사도 두번째 높은 문장은 '문장3' -> 0.8
'문장1' 기준으로 유사도 세번째 높은 문장은 '문장2' -> 0.5
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)벡터화한 텍스를 유사도를 구하는 과정에서 행과 열의 갯수는 같으므로
행과 열이 대칭 좌표는 같은 문장과의 비교로 1 의 유사도를 갖고
나머지는 각 서로 다른 문장과의 비교로 유사도를 나타냄
| 문장1 | 문장2 | 문장3 | |
|---|---|---|---|
| 문장1 | 1 | 0.3 | 0.8 |
| 문장2 | 0.3 | 1 | 0.5 |
| 문장3 | 0.8 | 0.5 | 1 |
'Ai > SikitLearn' 카테고리의 다른 글
| 05. (비지도학습)_K-Means (0) | 2025.04.03 |
|---|---|
| 04. (지도학습)_Logistic Regression(로지스틱 회귀) (0) | 2025.04.03 |
| 03. (지도학습)_Polynomial Regression(다항 회귀) (0) | 2025.04.03 |
| 02. (지도학습)_Multiple Linear Regression(다중 선형 회귀) (0) | 2025.04.03 |
| 01. (지도학습)_Linear Regression(선형 회귀) (0) | 2025.04.03 |